Contexte
En 2021, lorsque je travaillais pour Zenly sur le projet maplens, nous
recherchions de nouvelles idées de lens. Une lens consistait en l’affichage
d’informations complémentaires sur la carte de l’utilisateur, comme par exemple
les stations vélibs avec leurs états en temps réel, les toilettes publiques,
les cours de baskets, etc…
Nous voulions une lens encore plus “temps réel”, et qui serait dans l’actualité. Au même moment, une fameuse course de bateau autour du monde avait lieu. Nous avons donc eu l’idée de l’incorporer dans Zenly, ce qui aurait permis de suivre la position des bateaux en temps réel. Bien évidemment, il nous fallait d’abord un contrat avec les responsables avant de diffuser cela dans notre application. Le temps que ce contrat se fasse, pour ne pas perdre de temps, j’ai eu la tâche de préparer cette lens.
Pour cela, il me fallait accéder à leur flux en temps réel, qui était celui qu’ils utilisaient sur leur site web. Celui-ci était protégé, et voici en détails toutes les démarches et le raisonnement qui m’ont permis de contourner leurs sécurités.
Au final, le contrat ne s’est jamais fait, et la lens n’a jamais dépassé l’usage de la version de test, mais ça a été très intéressant à “casser”.
Dans tout l’article, le vrai nom du site a été remplacé par site-de-bateaux, pour éviter tout souci. Le but étant de présenter des méthodes d’analyse, et non pas de nuire.
Premier contact
Le seul site qui fournit la position des skippers en temps réel est:
https://www.site-de-bateaux.org/en/tracking-map. Quand on va sur leur site web et
qu’on ouvre la console de debugging, on peut voir qu’ils récupéraient leur flux
de données sur:
https://tracking2020.site-de-bateaux.org/data/race/tracker_reports.hwx?v=20201206165939.
Donc, dans un premier temps, je me suis naïvement dit qu’un simple curl et un
adaptateur suffirait pour alimenter ma lens. Je m’attendais à récupérer du json,
comme pour la plupart des lens. Mais… Non ! On récupere juste un blob de data
opaque. Si on applique la commande file dessus, celle-ci nous dit que ce
serait un fichier contenant une clé pgp. C’est vraiment étrange.
Ils ne veulent clairement pas partager cette information, et ils ont certainement une sorte de protection. Le fait que personne d’autres qu’eux ne diffuse cette information, montre qu’ils ont bien sécurisé leurs données (au moins suffisamment pour décourager qui que ce soit).
Analyse et reverse
Et si on essayait de contourner ?
Il s’avère qu’ils ont une application android sur le store. Donc, une solution possible, serait de télécharger cette application, de la décompiler et de comprendre comment ils lisent leur flux. Malheureusement, leur application est un simple navigateur web embarqué…
J’ai ensuite essayé d’autres pistes. Est-ce que le flux demande un token pour renvoyer une donnée intelligible ? Est-ce un problème de little/big endian ? Est-ce qu’il faut donner un bon “referer” dans les metadata pour que le site renvoie la bonne data ? Aucune de ces pistes n’a été concluante.
Il n’y a pas de possibilité de contourner cela facilement, on va devoir mettre les mains dans la technique et analyser le site en profondeur !
Première couche de protection
Tout leur javascript est “packé” et “minifié”, ce qui implique que le code est illisible et on ne peut pas aisément poser de breakpoints dessus. Ce n’est pas pratique, commençons par régler cela.
On va commencer par “unpacker” les javascripts. C’est assez simple à faire, on peut même le faire en ligne ici: https://lelinhtinh.github.io/de4js/
Maintenant que l’on a unpack leurs javascripts (hws.js, main.js, sig.js, viewer.js, viewer_extra.js), il faut qu’on utilise ces versions plutôt que celles du site officiel. Pour faire cela, une simple attaque “man in the middle” avec un proxy suffira. On va utiliser “Charles proxy 4.2.7”, ce qui va nous permettre de remplacer un fichier distant par une version locale de notre choix.
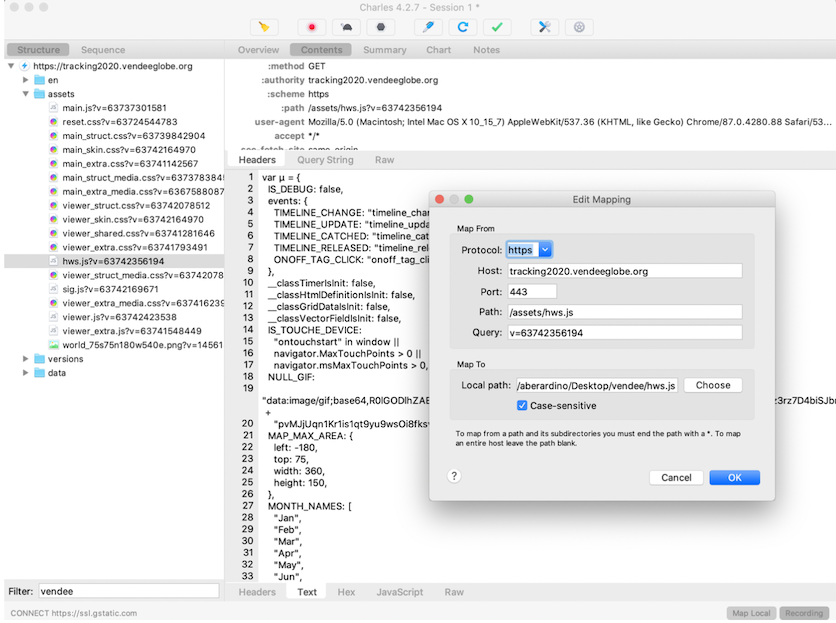
Lançons Chome avec une option pour ignorer les soucis de CORS:
/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome --ignore-certificate-errors
Ensuite, accédons au site. On voit maintenant que tous les fichiers javascripts ont bien été remplacés par les notres. On va pouvoir commencer à poser des breakpoints et lire leur code.
À noter qu’il semble que leur site web: https://www.site-de-bateaux.org/en/tracking-map est juste une frame par dessus cette page: https://tracking2020.site-de-bateaux.org/en/, donc on va juste se concentrer sur celle-ci.
Seconde couche de protection
En inspectant le code, on voit qu’une fonction loadHwxFile est utilisée pour
lire leurs données via leur API. En mettant un console.log() à la fin, on peut
maintenant voir leur données lisiblement ! Mais pour l’instant, on ne voit
aucune différence entre le code du site et le petit bout de code que j’ai écrit
en Golang pour tester leur API. Pourtant, leur code fonctionne, et le notre non.
Le code qui gère cette partie est le suivant:
loadHwxFile: function (url, datatype, callback) {
var xhr = new XMLHttpRequest();
xhr.open("GET", url, true);
xhr.responseType = "arraybuffer";
xhr.onload = function (e) {
if (this.status == 200) {
var arr = new UInt8Array(this.response);
var data = new TextDecoder("utf-8").decode(arr);
callback(
datatype == "json"
? eval("(" + data + ")") : datatype == "xml"
? $(data)
: data
;)
}
;}
xhr.send();
},
Ça ne se voit pas au premier coup d’oeil, mais quelque chose est bizarre avec ce
code. Tout d’abord, le this.response est un ByteBuffer, il n’est donc
normalement pas utile de le transformer ou de le caster en un Uint8array.
Commençons par retirer cette routine inutile. En faisant cela, le résultat est
le même que pour le petit exemple en Golang que j’avais écrit: ça ne fonctionne
pas !
Comment retirer un cast inutile peut-il drastiquement changer le comportement ? Je ne suis pas un expert javascript, est-ce que j’aurais loupé quelque chose dans la documentation ? Ça parait pourtant relativement standard. Faisons au plus simple, on va mettre ce petit bout de code dans un playground, et voir comment il réagit.
En faisant cela, j’obtiens alors une erreur: Uncaught ReferenceError: UInt8Array is not defined. Alors là, c’est étrange. Leur code fonctionne bien
et c’est un type tout à fait classique. Est-ce qu’il faudrait un import
particulier ? Est-ce qu’ils auraient une couche de compatibilité pour les
anciens navigateurs ?
Et là, ça m’a sauté au yeux: le nom du type ! Il est écrit UInt8Array au lieu
de Uint8Array (notez le i en majuscule). Alors ça, c’est vicieux ! Ils ont
créé une fonction customisée qu’ils ont déguisé sous une forme innocente.
Troisième couche de protection
Bon, on sait maintenant que cette fonction a été ajoutée au namespace global, il ne reste qu’à la trouver pour comprendre ce qu’elle fait. J’ai lancé une recherche dans tous les fichiers javascripts, mais je n’ai rien trouvé. Comment ont-ils fait cela ? Il semble que la fonction n’a jamais été redéfinie où que ce soit.
Pour localiser celle-ci, j’ai recouru à la bonne vieille méthode de la
dichotomie. On retire du code progressivement, pour isoler où cette fonction
aurait pu être définie. Finalement, par isolation, il semble que le morceau de
code soit localisé dans le fichier main.js. On ne sait pas encore où
exactement, mais ça réduit déjà pas mal le champs de recherche.
En lisant le code, rien de vraiment pertinent. Il n’y a aucune redéfinition.
Néanmoins, un petit morceau de code m’intrigue. Une image semble être chargée,
mais c’est fait via un eval. Ça me semble inutilement compliqué juste pour
faire ça.
_initNav: function () {
try {
var burgerImgDef = $("nav img").attr("src").split("/C/").slice(1);
for (var i = 0; i < 3; i++) {
eval(μ.base64.decode(burgerImgDef[i])); // <-- FISHY!!!
};
}
} catch (e) {
}
Quand on regarde l’image qui est censée être chargée, on peut clairement voir que c’est du base64, mais l’image ne se charge pas dans le debugger. C’est très suspicieux !
<nav>
<!-- some code -->
<div class="burger">
<div class="line"></div>
</div>
<div class="cross"></div>
<img src="data:image/png;base64,iVBOR[...]V0dXJuIF8weDdmNGF4N30=" /> </div>
</nav>
Si on décode la chaîne de caractères, on voit pourtant bien que c’est un PNG, et qu’il n’y a aucun code dedans.
PNG
���
IHDR���)���)���'���tEXtSoftware�Adobe ImageReadyqe<��"iTXtXML:com.adobe.xmp�����<?xpacket begin="" id="W5M0MpCehiHzreSzN
4z>T6\]]5>LnUwvvֺ%n1??^.~7>>c;:::N~6lM ۛ˧ΛHzmi&3\U|
]\\8exxƅFHp:#UUUKKKŪ3sjj
rșr03דNI.jsM54NjQ%(cL
P% 5p?QZ>ї1իNC3&( [p'f}w9Y
.PeXۉ %x2϶] /&1r(W_ifս|$[ZZkvZ]DXqt'˔k܀]=}_S<̦j^xt{{9@.ye#MZY&jޞ#vϳ5F)EZ3y.pk(�#\7_ݙ`m ic3FH"iE91x%[:///w!<P5&sDii^
gWt` �A9S��uZutt0LU B(3|L(60β1t^c=4?~ݛa^``;Յõk!B҈rM\n4*XL@.:Jx-tJXDzdީ?,qqXK{,?|400PSSW}{bbA3B`Ň)|I՚glʄRkYh̨v/**{0w
g`8քs0e-i$9ީnyy*r#,`Dtb0sCQRczN2m\Эm^XX�1^
Ύ'nؾ;w*JG
ONN677ljMbRXXcb /Ba~@xOa0P;Sb!p_b~,8q} K[bG�N%:����IENDB`/[˗LLL
[˗NL
АMN[˗NPOL
MMѐN[˗QNL
MPQܹݥ|aչѥ|Ռȥمȁ|Ռ|مȁ|Ռ|مȁ|Ռ|مȁ|Ռ| ȡمȁ|Ռ|Ռ|Ռ |Ռܥ|Ռࠥչѥ|Ռࠥمȁ|Ռ|Ռ|Ռx|ՌĤ|Ռx|Ռघ|Ռ|Ռ|Ռ|Ռ|Ռ|Ռ|Ռx|Ռ |Ռx|Ռɕɸչѥ|Ռ مȁ|Ռ|Ռx|Ռ̘|Ռࠤɕɸ|Ռ?vFrVF3
Mais, il y a une astuce ! On peut voir qu’ils ont mis plein de /c/ comme
délimiteurs. Le début de l’entête du png est valide, mais est suivi par 3
payloads secrets !
En découpant la grosse chaine de caractères en base 64 en 4 parties, et en les
décodant séparemment, on trouve 3 secrets après le payload initial. Affichons
maintenant ce qui est réellement évalué par eval:

La partie intéréssante est ici:
window.UInt8Array=function(_0x7f4ax2){var _0x7f4ax3= new Uint8Array(_0x7f4ax2);
C’est bien ça ! On voit enfin la redéfinition du UInt8Array. Donc ils ont
caché dans une balise d’image html, une png encodé en base64 dans lequel était
lui-même caché du code au milieu du header PNG… Bien alambiqué !
La code de la fonction nécessite un peu de travail pour être “reverse”, mais ça semble être un mini chiffrement personalisé.
Script intermédiaire
Avant de passer du temps à analyser et déchiffrer le code, testons d’abord que
ça fonctionne. On va juste extraire le code “brute” et le lancer via du
node.js.
Voici le code extrait:
_0xA0A0F0 = 0xFF8040;
_0x88FE88 = 0x7BC495;
_0xFE88AA = 0x4557FA;
_0xEE8080 = 0xD56AAF;
_0Xedc3 = function(_0xc5c0x2){
var _0xc5c0x3 = _0x88FE88;
var _0xc5c0x4 = _0xFE88AA;
var _0xc5c0x5 = _0xEE8080;
var _0xc5c0x6 = _0xA0A0F0;
for(var _0xc5c0x7 = 0; _0xc5c0x7 < _0xc5c0x2; ++_0xc5c0x7){
_0xc5c0x8();
}
function _0xc5c0x8(){
var _0xc5c0x9 =_0xc5c0x3;
_0xc5c0x9 ^= (_0xc5c0x9 << 11) & 0xFFFFFF;
_0xc5c0x9 ^= (_0xc5c0x9 >> 8) & 0xFFFFFF;
_0xc5c0x3 = _0xc5c0x4;
_0xc5c0x4 = _0xc5c0x5;
_0xc5c0x5 = _0xc5c0x6;
_0xc5c0x6 ^= (_0xc5c0x6 >> 19) & 0xFFFFFF;
_0xc5c0x6 ^= _0xc5c0x9;
}
return function(_0xc5c0xa){
var _0xc5c0xb = _0xc5c0xa ^ (_0xc5c0x3 & 0xFF);
_0xc5c0x8();
return _0xc5c0xb
}
}
_0xedc3 = ["\x6C\x65\x6E\x67\x74\x68"]; // "length"
UInt8Array = function(_0x7f4ax2) {
var _0x7f4ax3 = new Uint8Array(_0x7f4ax2);
var _0x7f4ax4 = _0Xedc3(_0x7f4ax3[0]);
var _0x7f4ax5 = (_0x7f4ax4(_0x7f4ax3[1]) << 16) + (_0x7f4ax4(_0x7f4ax3[2]) << 8) + (_0x7f4ax4(_0x7f4ax3[3])); var _0x7f4ax6 = 4;
var _0x7f4ax7 = new Uint8Array(_0x7f4ax5);
var _0x7f4ax8 = 0;
while (_0x7f4ax6 < _0x7f4ax3[_0xedc3[0]] && _0x7f4ax8 < _0x7f4ax5) {
var _0x7f4ax9 = _0x7f4ax3[_0x7f4ax6];
_0x7f4ax9 = (_0x7f4ax9 ^ (_0x7f4ax6 & 0xFF)) ^ 0xA3;
++_0x7f4ax6;
for (var _0x7f4axa = 7; _0x7f4axa >= 0; _0x7f4axa--) {
if ((_0x7f4ax9 & (1 << _0x7f4axa)) == 0) {
_0x7f4ax7[_0x7f4ax8++] = _0x7f4ax4(_0x7f4ax3[_0x7f4ax6++])
} else {
var _0x7f4axb = _0x7f4ax4(_0x7f4ax3[_0x7f4ax6]);
var _0x7f4axc = (_0x7f4axb >> 4) + 3;
var _0x7f4axd = (((_0x7f4axb & 0xF) << 8) | _0x7f4ax4(_0x7f4ax3[_0x7f4ax6 + 1])) + 1;
_0x7f4ax6 += 2;
for (var _0x7f4axe = 0; _0x7f4axe < _0x7f4axc; _0x7f4axe++) {
_0x7f4ax7[_0x7f4ax8] = _0x7f4ax7[_0x7f4ax8++ - _0x7f4axd]
}
}
if (_0x7f4ax6 >= _0x7f4ax3[_0xedc3[0]] && _0x7f4ax7[_0xedc3[0]] >= _0x7f4ax5) {
break
}
}
}
return _0x7f4ax7;
}
const https = require("https");
function call(url) {
https.get(url, function(res) {
var data = [];
res.on('data', function(chunk) {
data.push(chunk);
}).on('end', function() {
var arr0 = Buffer.concat(data);
var arr = new UInt8Array(arr0);
var jsText = new TextDecoder("utf-8").decode(arr);
console.log(jsText);
});
});
}
// Live data
call('https://tracking2020.site-de-bateaux.org/data/race/tracker_live.hwx')
// History of every snapshot
call('https://tracking2020.site-de-bateaux.org/data/race/tracker_reports.hwx')
// History of each boats path
call('https://tracking2020.site-de-bateaux.org/data/race/tracker_tracks.hwx')
Ce script peut être lancé via:
node caller.js
On constate que ça fonctionne bien. On va pouvoir passer à la partie analyse.
Reverse et déchiffrement
Pas mal de petites astuces ont été utilisées pour rendre le code le moins intelligible possible:
- Les variables intermédiaires inutiles comme:
_0xA0A0F0 = 0xFF8040;sont juste là pour embêter le lecteur. Elles n’ont aucune utilité et peuvent être remplacées directement. - Cette routine est un peu plus intéressante:
_0xedc3 = ["\x6C\x65\x6E\x67\x74\x68"];. On peut la traduire par["length"]. En javascript, on peut accéder aux méthode d’un objet, comme on accède aux éléments d’une map. Par exemplemyObject.lengthpeut être écrit:myObject["length"]. Donc l’expression_0x7f4ax3[_0xedc3[0]]peut se simplifier enlen(_0x7f4ax3). - La plupart des variables sont en fait des index et des tailles de buffer.
- Je n’ai pas trouvé le sens de certaines variables, mais ça n’est pas gênant, donc… “good enough !”.
Code golang final
Voici le code final, complètement nettoyé, avec un code (à peu près) lisible:
package main
import (
"fmt"
"io/ioutil"
"net/http"
)
const (
// LiveURL is the current state.
LiveURL = "https://tracking2020.site-de-bateaux.org/data/race/tracker_live.hwx"
// ReportsURL is the history of every snapshot.
ReportsURL = "https://tracking2020.site-de-bateaux.org/data/race/tracker_reports.hwx"
// TracksURL is the history of each boats path.
TracksURL = "https://tracking2020.site-de-bateaux.org/data/race/tracker_tracks.hwx"
)
// GetPayloadFromURL get bytes from a remote url ressource.
func GetPayloadFromURL(payloadURL string) ([]byte, error) {
response, err := http.Get(payloadURL)
if err != nil {
return nil, err
}
defer response.Body.Close()
data, err := ioutil.ReadAll(response.Body)
if err != nil {
return nil, err
}
return data, nil
}
// initBufferFunc is the init function for the decipher.
var initBufferFunc = func(size int) func(v int) int {
part1 := 0x7BC495
part2 := 0x4557FA
part3 := 0xD56AAF
part4 := 0xFF8040
subF := func() {
tmp := part1
tmp ^= (tmp << 11) & 0xFFFFFF
tmp ^= (tmp >> 8) & 0xFFFFFF
part1 = part2
part2 = part3
part3 = part4
part4 ^= (part4 >> 19) & 0xFFFFFF
part4 ^= tmp
}
for i := 0; i < size; i++ {
subF()
}
return func(v int) int {
var res = v ^ (part1 & 0xFF)
subF()
return res
}
}
// decipher decodes the protected payload of xxxxx API.
func decipher(buf []byte) []byte {
if len(buf) == 0 {
return []byte{}
}
bufferFunc := initBufferFunc(int(buf[0]))
bufferSize := (bufferFunc(int(buf[1])) << 16) + (bufferFunc(int(buf[2])) << 8) + (bufferFunc(int(buf[3])))
bufIndex := 4
dest := make([]byte, bufferSize)
destIndex := 0
for bufIndex < len(buf) && destIndex < bufferSize {
currentPos := buf[bufIndex]
currentPos = (currentPos ^ (byte(bufIndex) & 0xFF)) ^ 0xA3
bufIndex++
for i := 7; i >= 0; i-- {
if (currentPos & (1 << uint(i))) == 0 {
dest[destIndex] = byte(bufferFunc(int(buf[bufIndex])))
destIndex++
bufIndex++
} else {
_0x7f4axb := bufferFunc(int(buf[bufIndex]))
_0x7f4axc := (_0x7f4axb >> 4) + 3
_0x7f4axd := (((_0x7f4axb & 0xF) << 8) | bufferFunc(int(buf[bufIndex+1]))) + 1
bufIndex += 2
for j := 0; j < _0x7f4axc; j++ {
dest[destIndex] = dest[destIndex-_0x7f4axd]
destIndex++
}
}
if bufIndex >= len(buf) && len(dest) >= bufferSize {
break
}
}
}
return dest
}
func extractData() (string, error) {
data, err := GetPayloadFromURL(LiveURL)
if err != nil {
return "", err
}
return string(decipher(data)), nil
}
func main() {
json, err := extractData()
if err != nil {
panic(err)
}
fmt.Println(json)
}
Pour le tester, il suffit simplement de remplacer les site-de-bateaux par le vrai nom du site, et de lancer le programme via:
go run main.go